optunaとは?
optunaは機械学習において、「ハイパーパラメータの調整」を効率的に行うためのpythonライブラリです。
「対象データ・モデルに対してどのハイパーパラメータが良いか」を調べる際、他にある手法としては「グリッドサーチ」があります。グリッドサーチは(指定範囲を)全探索する手法であり、「全部調べるので時間や負荷がかかる」のがデメリットです。
対して、本題のoptunaでは「ベイズ最適化」の手法を用いており、それは「過去の探索結果を踏まえて、確率的に”より精度が良い”と推測されるパラメータ値を探索していく」形であり、グリッドサーチに比べ効率的に探索が行えます。
optunaはベイズ最適化の実施や探索記録の可視化を簡単に実装できるものであり、今回はその実装をしてみたいと思います。
※optunaやベイズ最適化の詳細について、参考となる書籍を下記記事に載せております。深堀りする際に参考になればと思います。
optunaの実装
0.optuna関連のライブラリをインストール
単に最適化を実施するだけでしたら「optuna」のみで十分ですが、可視化(optuna.visualization)を行う場合は、残りの3つもインストールが必要です。
# install
!pip install optuna
!pip install plotly
!pip install kaleido
!pip install nbformat1.データ作成
まず、学習に使うデータを作成します。今回はタイタニックデータを使います。
# import
import random
import numpy as np
import pandas as pd
import seaborn as sns
import optuna
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, roc_auc_score, accuracy_score
import matplotlib.pyplot as plt
from IPython.display import display
# data (チューニング過程を比較したいため、あえて精度が悪くなるようにカラムをランダムで削除)
target_col = "survived"
origin_data = sns.load_dataset('titanic')
random.seed(1)
ext_feature_idx = random.sample([i for i in range(1, len(origin_data.columns))], 5)
origin_data = origin_data.iloc[:, [0] + ext_feature_idx]
print(origin_data.survived.value_counts())
display(origin_data.head())
display(origin_data.describe(include="all"))
# preprocessing
data = origin_data.copy()
if "who" in data.columns:
data = data.drop(columns=["who"])
if "class" in data.columns:
data["class"] = data["class"].apply(lambda x: 1 if x == "First" else (2 if x == "Second" else 3))
for _col in ["sex", "adult_male", "alive", "alone"]:
if _col in data.columns:
data[_col] = data[_col].apply(lambda x: 1 if x in [True, "yes", "male"] else 0)
one_hot_cols = ["embarked", "deck", "embark_town"]
for _col in one_hot_cols:
if _col in data.columns:
data[_col] = data[_col].apply(lambda x:x.lower() if type(x) == str else x)
data = pd.get_dummies(data, columns=[_col], dummy_na=True)
data = data.fillna(data.mean())
display(data.head().T)
# train, valid data
features = [_col for _col in data.columns if _col != target_col]
X = data[features].values
y = data[target_col].values
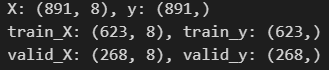
print(f"X: {X.shape}, y: {y.shape}")
train_X, valid_X, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
print(f"train_X: {train_X.shape}, train_y: {train_y.shape}")
print(f"valid_X: {valid_X.shape}, valid_y: {valid_y.shape}")
2.optunaで最適化を実施
最適化は下記の手順で行えます。
1:目的関数値を返す関数を定義(下記では「objective」)
→引数は(optuna内で1回の試行情報を持つobject)「trial」を指定し、関数内では、調整したパラメータを関数「trial.suggest_xxx」で呼び出す形にし、モデル初期化/ 学習/ 評価を実装し、戻り値は(最適化の対象となる)目的関数値を返す形にします。
2:create_study
→(一連の最適化情報を持たせる)studyを初期化します。引数「direction」は「目的関数値を最大化したいのか、最小化したいのか?」を指定します。(今回は最大化)デフォルト値は「minimize」(最小化)であることに注意です。
3:optimize
→最適化の実施
4:best_params, best_value
→最適化の結果、目的関数値が最も良かった時のパラメータと目的関数値を上記で得る事ができます。
# optuna
def objective(trial):
# clf_name = trial.suggest_categorical("clf", ["lgb", "rf"])
clf_name = "lgb"
if clf_name == "lgb":
# pref = "lgb_"
pref = ""
class_weight_str = trial.suggest_categorical(f"{pref}class_weight", ["balanced", "none"])
model = lgb.LGBMClassifier(
max_depth=trial.suggest_int(f"{pref}max_depth", 2, 128),
learning_rate=trial.suggest_float(f"{pref}learning_rate", 0.001, 0.1),
n_estimators=trial.suggest_int(f"{pref}n_estimators", 2, 128),
importance_type=trial.suggest_categorical(f"{pref}importance_type", ["split", "gain"]),
class_weight=(class_weight_str if class_weight_str != "none" else None),
)
# else:
# pref = "rf_"
# class_weight_str = trial.suggest_categorical(f"{pref}class_weight", ["balanced", "none"])
# model = RandomForestClassifier(
# max_depth=trial.suggest_int(f"{pref}max_depth", 2, 128),
# n_estimators=trial.suggest_int(f"{pref}n_estimators", 2, 128),
# criterion=trial.suggest_categorical(f"{pref}criterion", ["gini", "entropy", "log_loss"]),
# class_weight=(class_weight_str if class_weight_str != "none" else None),
# )
model.fit(train_X, train_y)
valid_pred = model.predict(valid_X)
valid_proba = model.predict_proba(valid_X)[:,1]
# [auc]
# auc = roc_auc_score(valid_y, valid_proba)
# [acc by valid]
# obj_value = accuracy_score(valid_y, valid_pred)
# [acc by cv]
acc_np = cross_val_score(model, X, y, cv=4)
obj_value = acc_np.mean()
return obj_value
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=50)
best_params = study.best_params
best_value = study.best_value
# best
print(f"best_params:\n {best_params}")
print(f"best_value:\n {best_value}")
3.探索結果の可視化
探索結果の詳細を下記で確認することができます。
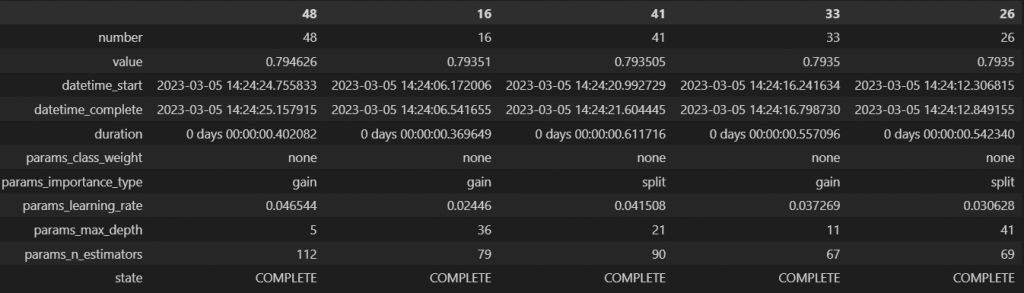
1:[df] study.trials_dataframe()
→各試行時のパラメータ値、目的関数値等を記録したデータフレーム。
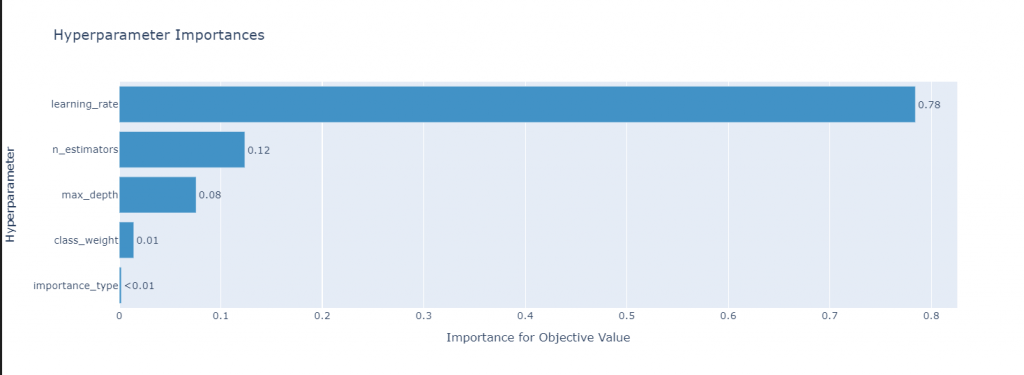
2:[graph] optuna.visualization.plot_param_importances()
→パラメータの重要度を可視化。
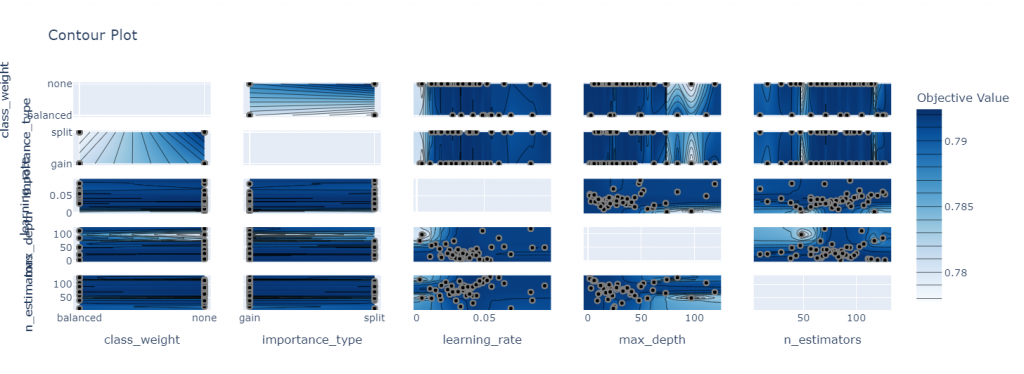
3:[graph] optuna.visualization.plot_contour()
→パラメータ空間における目的関数値の等高線を可視化。
# all trial as df
trial_df = study.trials_dataframe()
display(trial_df.sort_values(by="value", ascending=False).head().T)
optuna.visualization.plot_param_importances(study=study).show()
optuna.visualization.plot_contour(study=study).show()
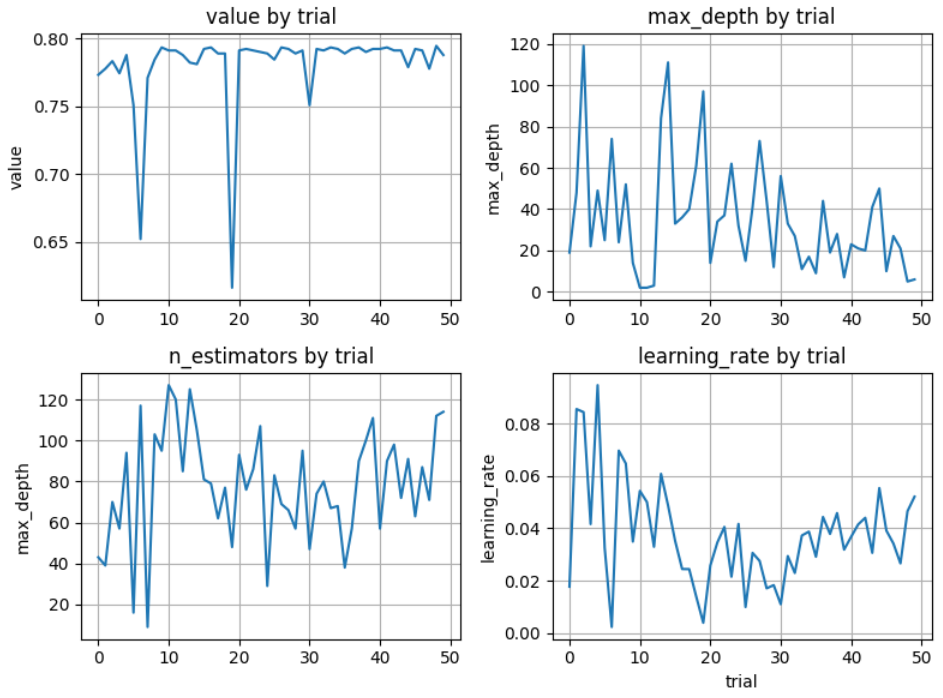
fig, axes = plt.subplots(2,2, figsize=(8,6))
axes = axes.ravel()
trial_df.sort_values(by="number")["value"].plot(ax=axes[0])
trial_df.sort_values(by="number")["params_max_depth"].plot(ax=axes[1])
trial_df.sort_values(by="number")["params_n_estimators"].plot(ax=axes[2])
trial_df.sort_values(by="number")["params_learning_rate"].plot(ax=axes[3])
plt.xlabel("trial")
axes[0].set_title("value by trial")
axes[0].set_ylabel("value")
axes[0].grid()
axes[1].set_title("max_depth by trial")
axes[1].set_ylabel("max_depth")
axes[1].grid()
axes[2].set_title("n_estimators by trial")
axes[2].set_ylabel("max_depth")
axes[2].grid()
axes[3].set_title("learning_rate by trial")
axes[3].set_ylabel("learning_rate")
axes[3].grid()
plt.tight_layout()
plt.show()