lightGBM等の決定木モデルでは、「各説明変数がどのくらい重要視されているか?」を数値化したものとして重要度があります。
今回は、下記前提(基本的なモデル作成フロー)の後続として、重要度チェックを実装したいと思います。
前提: データ準備~モデル作成
下記記事の通りに「データ準備からモデル作成まで行った後」として、話を進めます。
参考: 決定木、重要度の詳細
下記2つの記事をご参照ください。
特徴量の重要度を取得・表示
属性「feature_importances_」で重要度を取得できます。
ただ、(モデルには、データフレームでなくnp.arrayを入力して学習しているので)説明変数名は別途付与する必要があります。
なので、一例として下記の通りに実装します。
# [前提]=============================================
# TARGET_COL = "survived"
# FEATURE_COLS = [col for col in mldata_df.columns if col != TARGET_COL]
# model = LGBMClassifier()
# model.fit(X_train, y_train)
# =============================================
importance_df = pd.DataFrame(
{
"feature": FEATURE_COLS,
"importance": model.feature_importances_,
}
).sort_values("importance", ascending=False)
importance_df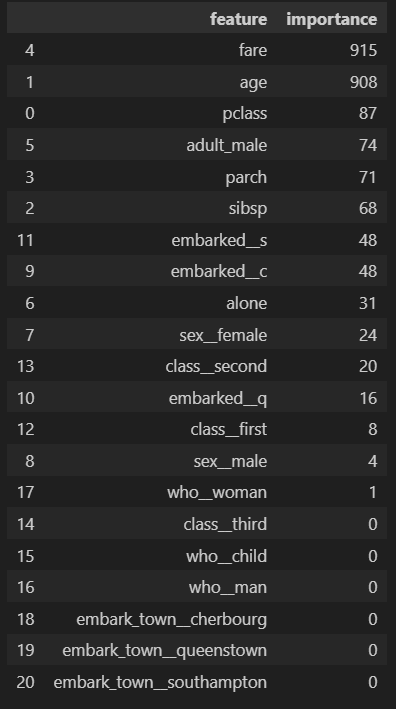
考察
まず前提として、重要度の数値は何を意味しているか踏まえましょう。
結論、今回の場合は「分岐(split)に何回使われたか?」(★)を意味します。
※ここで、上記の参考記事「【決定木】重要度」をご確認いただいた方は、その記事の重要度(情報利得)と上記★は別であることに気づくと思います。
ポイントは、下記2点であり、それらの結果今回は上記★が結論となります。
①LGBMClassifierの引数「importance_type」で重要度のタイプ(分岐回数、情報利得)を決められる。(分岐回数にする場合は「split」、情報利得にする場合は「gain」)
②importance_typeのデフォルト値は「split」
さて、本題の解釈ですが、
重要度を見ると fare や age が圧倒的に高い事が分かります。
重要度では「値の大小と目的変数の大小の関係性」までは分からないので、ここではあくまで仮説ですが、(救助の優先順位を想像するに)「階級が高い人や子供・老人が生き残りやすい」という特徴がありそうです。
そういう感じで、「目的変数と特徴量の関係度合い」を確認したり、あるいは(ドメイン知識を踏まえた時に)「モデルが適切であるか?(予測で使えると思えない変数が異様に使われていないか?)」を確認したりする際に重要度は活用できます。