optunaというライブラリは、(ベイズ最適化等を用いて)ハイパーパラメータのチューニングを効率的に行えるものです。今回は、下記前提(基本的なモデル作成フロー)の後続として、optunaでチューニングを行ってモデル改善を試みたいと思います。
前提: データ準備~モデル作成
下記記事の通りに「データ準備からモデル作成まで行った後」として、話を進めます。
本題: チューニングしてモデル再作成
上記前提でモデルを作りましたが、より精度高いものを目指して、ハイパーパラメータをoptunaでチューニングしていきます。
尚、optunaの実装方法に関する詳細は、下記記事にまとめましたので参考にしていただければと思います。
1.目的関数を定義
「何をもって良し悪しを決め、探索するか?」を定義します。
今回は(validデータの)f1値を返す形にします。(つまり、f1値が良くなるように探索させます。)
optunaを知ったばかりの方へ、引数(trial) や suggest_xxx が何か疑問に感じるかもしれませんが、一旦は「optunaを使う際の書き方」と認識いただければと思います。詳しく知りたい方は上記記事をご参照ください。
import optuna
from lightgbm import LGBMClassifier
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score,
confusion_matrix,
roc_auc_score,
)
# 目的関数を定義。今回はf1を設定。
def objective(trial):
model = LGBMClassifier(
max_depth=trial.suggest_int(f"max_depth", 2, 300),
learning_rate=trial.suggest_float(f"learning_rate", 0.001, 0.1, log=True),
n_estimators=trial.suggest_int(f"n_estimators", 2, 300),
min_child_samples=trial.suggest_int(f"min_child_samples", 20, 200),
importance_type=trial.suggest_categorical(f"importance_type", ["split", "gain"]),
)
model.fit(X_train, y_train)
pred_valid = model.predict(X_valid)
f1_valid: float = f1_score(y_valid, pred_valid)
return f1_valid
2. チューニング実施
定義した目的関数を入力として、チューニング実行(study.optimize)をします。ここで作った study は「チューニング記録を保持するもの」です。
今回の目的関数はf1ということで最大化を目指すので、「direction=”maximize”」にします。
n_trials は 探索回数であり、今回は 100 にしてみたいと思います。
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)study.optimize を実行するとログに下図のような「各trialにて使ったパラメータ値と結果、そして、そこまでのtrialにおけるベスト結果」が次々に出力されていきます。
3. 得られたベストなパラメータを使って、モデルを再作成
探索してきた結果として、最も目的関数値が良かった(validデータのf1が大きかった)時のパラメータは、study.best_params で確認できます。
それを用いて、上記前提と同じようにモデルを作成し、各種指標を確認してみます。
best_params = study.best_params
best_value = study.best_value
print(f"best_params: {best_params}")
print(f"best_value: {best_value}")
print()
best_model = LGBMClassifier(**best_params)
best_model.fit(X_train, y_train)
# predict
pred_valid = best_model.predict(X_valid)
score_valid = best_model.predict_proba(X_valid)[:, 1]
print(f"pred_valid: {pred_valid.shape}, data: {pred_valid[:5]}")
print(f"score_valid: {score_valid.shape}, data: {score_valid[:5]}")
print()
# 精度チェック
print(f"accuracy_score: {accuracy_score(y_valid, pred_valid):.2%}")
print(f"precision_score: {precision_score(y_valid, pred_valid):.2%}")
print(f"recall_score: {recall_score(y_valid, pred_valid):.2%}")
print(f"f1_score: {f1_score(y_valid, pred_valid):.2%}")
print(f"roc_auc: {roc_auc_score(y_valid, score_valid):.2%}")
sns.heatmap(confusion_matrix(y_valid, pred_valid), annot=True, cmap='Blues')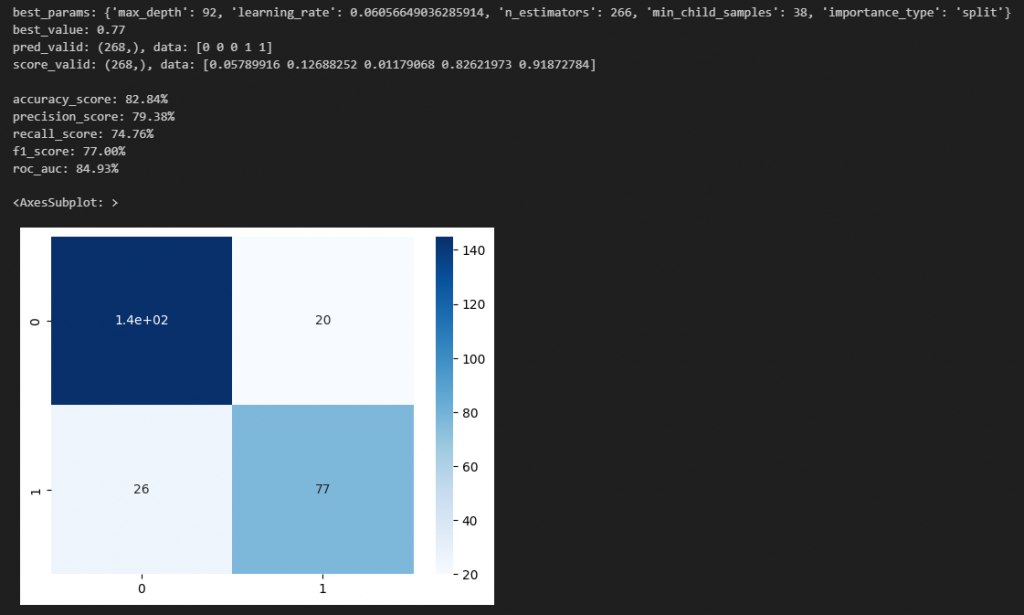
結果、(上記前提の時に比べ)下記の通り、下記指標の全てが良くなりました。
このように、optunaを使う事でチューニングが簡単に実装できます。
・accuracy_score: 82.84% ( ← 80.97% )
・precision_score: 79.38% ( ← 77.08% )
・recall_score: 74.76% ( ← 71.84% )
・f1_score: 77.00% ( ← 74.37% )
・roc_auc: 84.93% ( ← 84.17% )