ここでは、pythonやモデル手法を学び、モデル作成をこれから始めるような方に向けて、基本的な実装手順を記載します。
前提: モデリング内容
kaggle等で有名な「タイタニック」のデータを用いて、「生存した人(survived=1)」を予測するモデルを、「lightGBM」で作りたいと思います。
データはkaggle(https://www.kaggle.com/c/titanic/data)でも取得できますし、seabornライブラリより取得することもできます。
今回は下記の形で、seabornよりデータを取得して話を進めたいと思います。
import pandas as pd
import seaborn as sns
in_df = sns.load_dataset('titanic')
in_df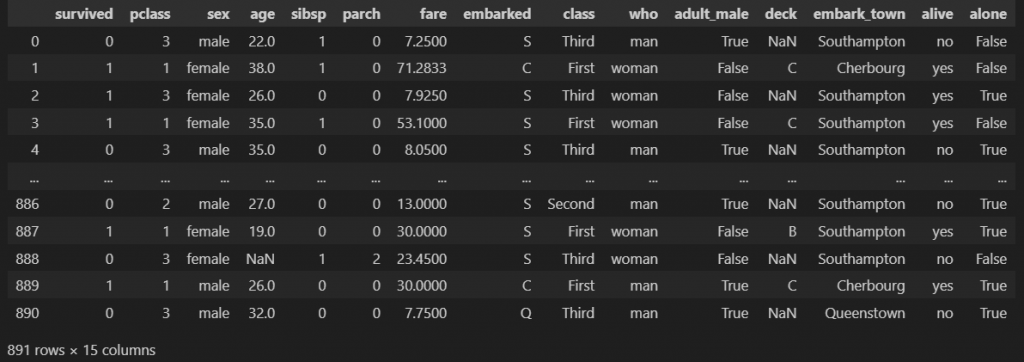
モデル作成
1.データ俯瞰
データ全体を俯瞰してみます。
具体的には、各列について「数値か文字列か?」(※1)や「欠損がどのくらい存在するか?」(※2)を確認します。
関数「describe(include=”all”)」を用いる事で簡単に俯瞰結果を確認できます。
(※1)文字列や名義尺度の場合はダミー変数化(one-hot)等にする
(※2)欠損が多い場合は、「モデルに使わない」等を検討する
desc_df = in_df.describe(include="all").T
desc_df["null_ratio"] = (len(in_df) - desc_df["count"]) / len(in_df)
desc_df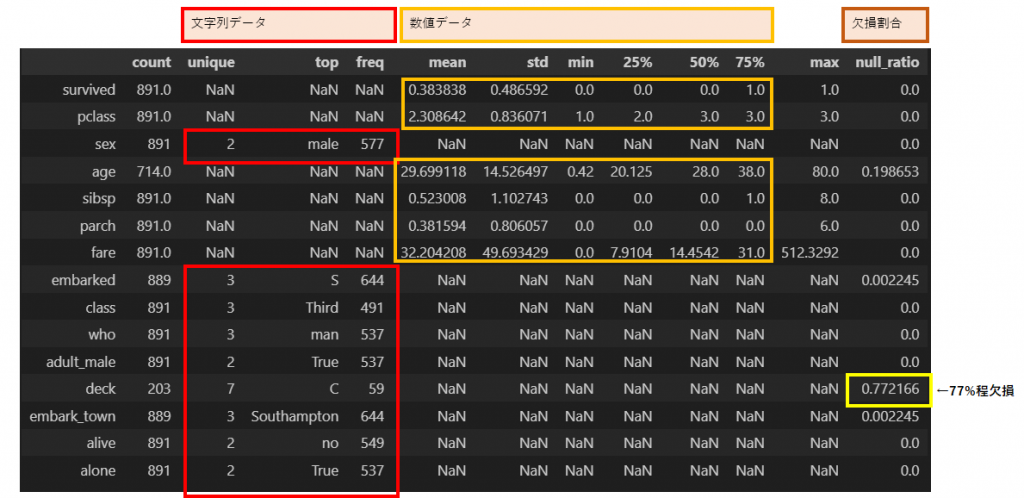
2.データ加工
モデリングでは基本的に数値データにする必要があります。
データ俯瞰結果を踏まえて、(今回は簡単に)下記の加工を行ってみます。
- 文字列データ: ダミー変数化(get_dummies)
- boolデータ: 0,1にする(True ⇒ 1)
- 欠損が多い変数: 除外(今回は変数「deck」を除外)
- (俯瞰結果ではないが、)aliveは目的変数(survived)と同じ意味らしいので除外
print(f"in_df len: {len(in_df)}")
print(f"in_df cols len: {len(in_df.columns)}")
mldata_df = in_df.copy()
# 変数除外:欠損が多い変数 + alive
NULL_RATIO_MAX = 0.7
remove_cols = ["alive"] + list(desc_df[desc_df["null_ratio"] > NULL_RATIO_MAX].index)
print(f"remove_cols: {remove_cols}")
mldata_df = mldata_df.drop(columns=remove_cols)
# 文字列データをダミー変数化
str_cols = [
col for col in list(desc_df[desc_df["mean"].isnull()].index)
if col in mldata_df.columns
]
print(f"str_cols: {str_cols}")
dummy_df = pd.get_dummies(mldata_df[str_cols], dummy_na=False, prefix_sep="__")
mldata_df = pd.concat(
[
mldata_df.drop(columns=str_cols),
dummy_df,
],
axis=1,
)
mldata_df.columns = [
col.lower() for col in mldata_df.columns
]
# adult_male, alone は bool値なので 0,1にする
for col in ["adult_male", "alone"]:
mldata_df[col] = mldata_df[col].apply(lambda _bool: 1 if _bool else 0)
print(f"mldata_df len: {len(mldata_df)}")
print(f"mldata_df cols len: {len(mldata_df.columns)}")
mldata_df.head(3)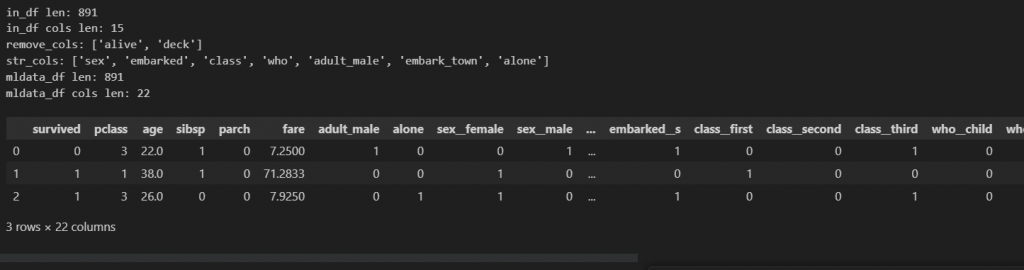
3.データ分割(train, valid)
汎化性能を持たせるために、モデルで学習させるデータ(train)と検証に使うデータ(valid)に分割します。
from sklearn.model_selection import train_test_split
TARGET_COL = "survived"
FEATURE_COLS = [col for col in mldata_df.columns if col != TARGET_COL]
# train + valid
X = mldata_df[FEATURE_COLS].values
y = mldata_df[TARGET_COL].values
X_train, X_valid, y_train, y_valid = train_test_split(
X, y,
test_size=0.3,
random_state=1,
shuffle=True,
stratify=y,
)
print(f"X: {X.shape}")
print(f"y: {y.shape}")
print(f"X_train: {X_train.shape}")
print(f"y_train: {y_train.shape}")
print(f"X_valid: {X_valid.shape}")
print(f"y_valid: {y_valid.shape}")
print(f"target=1 ratio (train): {y_train.sum()/len(y_train):.2%}")
print(f"target=1 ratio (valid): {y_valid.sum()/len(y_valid):.2%}")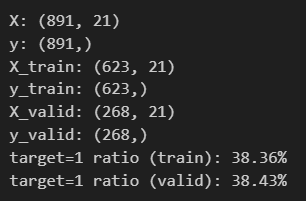
4.モデル学習
lightGBMを使ってモデル学習を行います。
from lightgbm import LGBMClassifier
model = LGBMClassifier()
model.fit(X_train, y_train)5.モデル検証
検証用データ(valid)を用いて、モデル精度を検証します。
指標値を踏まえると下記の事が分かります。
・accuracyより、80%程のデータについて予測が正解
・precisionより、生き残った(survived=1)と予測したデータの内、正解だったものが77%程。
・recallより、実際生き残った(survived=1)データの内、予測が正解だったものが72%程
精度を上げるにあたって、ドメイン知識等を踏まえてデータ加工を見直したり、(optuna等で)モデルのハイパーパラメータをチューニングしたりします。
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score,
confusion_matrix,
roc_auc_score,
)
# predict
pred_valid = model.predict(X_valid)
score_valid = model.predict_proba(X_valid)[:, 1]
print(f"pred_valid: {pred_valid.shape}, data: {pred_valid[:5]}")
print(f"score_valid: {score_valid.shape}, data: {score_valid[:5]}")
print()
# 精度チェック
print(f"accuracy_score: {accuracy_score(y_valid, pred_valid):.2%}")
print(f"precision_score: {precision_score(y_valid, pred_valid):.2%}")
print(f"recall_score: {recall_score(y_valid, pred_valid):.2%}")
print(f"f1_score: {f1_score(y_valid, pred_valid):.2%}")
print(f"roc_auc: {roc_auc_score(y_valid, score_valid):.2%}")
sns.heatmap(confusion_matrix(y_valid, pred_valid), annot=True, cmap='Blues')
6.深堀り
色々な深堀り方がありますが、一例としては下記記事をご参照ください。