pandasを用いてデータ加工を行う際、関数「apply」は便利です。
簡単に使い方を記載します。
[前提] データ準備
下記のデータフレーム(列: a, b)を用意し、それを入力として加工を行ってみます。
import pandas as pd
# data
LEN = 5
data = {
"a": [i for i in range(LEN)],
"b": [(i * 100) for i in range(LEN)],
}
df = pd.DataFrame(data)
df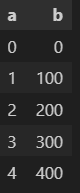
applyを用いてデータ加工
①入力: 1列、出力: 1列
シンプル「第一引数に関数(ここではlambda)を設定」すれば良いです。
※下記は、a列の値に5を足す場合。
# [加工] input: 1列, output: 1列
df["a"].apply(
lambda a_val: a_val + 5
)
②入力: 複数列、出力: 1列
上記①に加え、「axis=1」を設定します。
そうすることで、第一引数の関数において、入力(row)が「1行分の辞書」と見なされます。
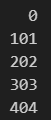
※下記は、a列とb列を足す場合。
# [加工] input: 複数列, output: 1列
df.apply(
lambda row: (row["a"] + row["b"]),
axis=1,
)
③入力: 複数列、出力: 複数列
上記②に加え、「result_type=”expand”」を設定します。
※下記は、(a列 + b列)と(b列 – a列)を同時に算出する場合。
# [加工] input: 複数列, output: 複数列
df.apply(
lambda row: {
"sum": (row["a"] + row["b"]),
"diff": (row["b"] - row["a"])
},
axis=1,
result_type="expand",
)